【仅供内部供应商使用,不提供对外解答和培训】
【仅供内部供应商使用,不提供对外解答和培训】
擂主奖:3000元 + 永久30%收益分成;参与奖:900元 ·············完成该课题即可获得参与奖,并进入挑战赛;该课题得分最高者为擂主;其它奖励见大赛报名页
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots.txt文件需要放在某一域名站点的根目录下,搜索引擎会默认读取。
finereport自带的”决策平台“本身就是javaweb工程,为了方便员工在公司外使用,有时候公司会部署到外网,有概率被搜索引擎收录,在搜索企业关键词时被显示,造成数据泄露损失。
接下来到你了,请在工程中生成robots.txt文件或者通过路由模拟这个文件,帮助搜索引擎正确处理报表工程中的内容。
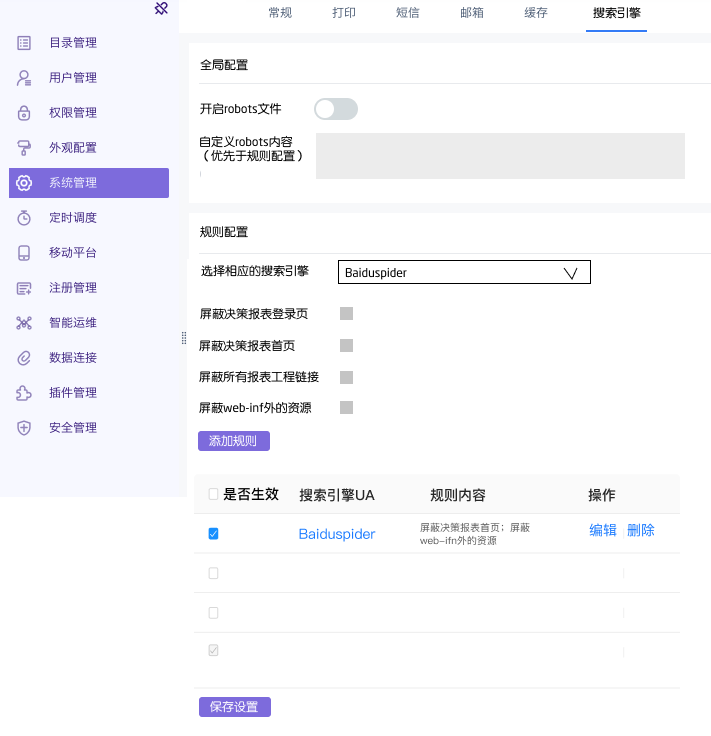
必须在系统管理中增加相关的配置项。原型图设计稿如下。配色和样式方案可以自由发挥。额外功能加分。
Overview
Content Tools